This article helps you to understand the difference between Rebuild and Reorganize, how they are different, when to choose Rebuild the Index or Reorganize the Index, what is fill factor and what it does and more importantly we will understand all these things with Demo.
Introduction
This is the third and final installation of the series of fragmentation, in the first part we learn about external and internal fragmentation, how writes can be a problem for your server.
The second part mainly deals with the read problems with the fragmentation.
So far we have talked only about problems associated with the fragmentation, in this article we will consider how we can deal with the fragmentation.
REBUILD AND REORGANIZING THE INDEX
To reduce fragmentation from the indexes you have two options in hand Rebuild and Reorganize, both serve the same purpose, it removes the fragmentation from the index but there are some difference between them, we will learn about them one by one, follow up by demos, then we will look into the difference between the both processes.
REBUILD INDEX
First we will look into what Rebuild process does to the index in bullet point list:
- Rebuild drops the existing index and recreate a brand new index.
- Rebuild can run in parallel (Enterprise/Developer version only), this is a great feature for large table/indexes, so it leverage all CPUs and perform the operation faster.
- Since Rebuild creates a fresh index, thus it creates new and fresh statistics on the underlying index.
- If rebuild is performed offline then the index is not available until the rebuild process has completed, and to perform the online rebuild you should have enterprise/developer edition only.
- Rebuild index process generates nearly same size of log records as the size of the index.
- You can specify a fill factor setting while rebuilding the index.
- The rebuild is an atomic operation, means if you cancel it in between, it will stop and reflect no changes.
Rebuild Index Bullet point DEMO: I do not like theories, I love practical, thus we will see all the above bullet point in the demo as well, to conduct the demo we are creating a store procedure which will create a fragmented table, we will use the fragmented table for demo purpose,
Here is the script.
CREATE PROCEDURE [dbo].[DropCreateAndFragmented]
AS
begin
IF EXISTS ( SELECT OBJECT_ID('[DBO].Fragmented'))
DROP TABLE [DBO].Fragmented
CREATE TABLE [DBO].Fragmented (
Primarykey int NOT NULL,
Keycol VARCHAR(50) NOT NULL
,SearchCol INT
,SomeData char(20),
Keycol2 VARCHAR(50) NOT NULL
,SearchCol2 INT
,SomeData2 char(20),
Keycol3 VARCHAR(50) NOT NULL
,SearchCol3 INT
,SomeData3 char(20))
INSERT INTO [DBO].Fragmented
SELECT
n,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
FROM Numbers WHERE N/2.0=N/2
AND N<500001
CREATE UNIQUE CLUSTERED INDEX CI_Fragmented ON [DBO].Fragmented (Primarykey)
SELECT OBJECT_NAME(OBJECT_ID) Table_Name, index_id,index_type_desc,index_level,
avg_fragmentation_in_percent fragmentation, avg_page_space_used_in_percent Page_Density, page_count,Record_count
FROM sys.dm_db_index_physical_stats
(db_id('tutorialsqlserver'), object_id ('Fragmented'), null, null,'DETAILED')
Where
Index_Level =0 and Index_Id=1
INSERT INTO [DBO].Fragmented
SELECT
n,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
FROM Numbers WHERE N/2.0!=N/2
AND N<500001
SELECT OBJECT_NAME(OBJECT_ID) Table_Name, index_id,index_type_desc,index_level,
avg_fragmentation_in_percent fragmentation, avg_page_space_used_in_percent Page_Density, page_count,Record_count
FROM sys.dm_db_index_physical_stats
(db_id('tutorialsqlserver'), object_id ('Fragmented'), null, null,'DETAILED')
Where
Index_Level =0 and Index_Id=1
endNow, let us run the above store procedure to create a fragmented clustered index.
EXEC[dbo].[DropCreateAndFragmented]
Demo: Rebuild Is Offline ProcessNow we have a fragmented table which is highly fragmented, to see that whether rebuild creates new index or not we will look into the index`s Object and pages IDs, then we will perform Rebuild and then check the Index Object and Pages IDs again.
But in this first section we will look does rebuild is an offline process (Index are not available during index rebuild).
So, let us look into the index pages using sys.dm_db_database_page_allocations DMV, if you are running this demo on lower than SQL Server 2012 then you can use this code to pull the IND output into a table.
SELECT
object_id AS ObjectID ,index_id AS IndexID ,page_type AS PageType ,page_level AS IndexLevel
,previous_page_page_id AS PrevPagePID ,allocated_page_page_id AS PagePID,next_page_page_id AS NextPagePID
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Fragmented'), 1, NULL, 'DETAILED')
WHERE is_allocated = 1 and page_type=1 and page_level=0
ORDER BY previous_page_page_id;
Look at the Object ID, if Rebuild process creates a new index, then we will see a new Object ID and different set of pages in the index, but first check whether Rebuild is offline process or not.
Ok, because we have a small clustered index, it will rebuild very quickly and we need to check whether rebuild is off-line process or not, we will run it in a loop 5 times and simultaneously we will run a simple select query in another query window to check whether the index is available during the rebuild process or not.
see the query and result below:
--QUERY WINDOW 1
DECLARE @LOOPCOUNT INT
SET @LOOPCOUNT=1
WHILE( @LOOPCOUNT <=5)
BEGIN
ALTER INDEX ALL ON Fragmented REBUILD --WITH (ONLINE=ON)
SET @LOOPCOUNT= @LOOPCOUNT+1
END
COMMIT

--QUERY WINDOW 2 (SIMULTANEOUSLY RUN WITH REBUILD)
SET STATISTICS TIME ON
SELECT COUNT_BIG(*) FROM Fragmented where Primarykey=1000
SET STATISTICS TIME ON

This is a very simple select query and it should finish immediately, but it kept on running until the rebuild loop hasn`t finished, or we can say when it is Offline and are in maintenance mode.
Demo: Rebuild Can Run In Online If You Are On Enterprise/Developer Version
In this demo we will again use the loop and Rebuild the Index, but this time we will specify keyword “online=on“ with rebuilding syntax and according to the theory which presented in the bullet point above, the Index should be available during the rebuild process (Don't forget it is an Enterprise/Developer feature only).
--QUERY WINDOW 1
DECLARE @LOOPCOUNT INT
SET @LOOPCOUNT=1
WHILE( @LOOPCOUNT <=5)
BEGIN
ALTER INDEX ALL ON Fragmented REBUILD WITH (ONLINE=ON)
SET @LOOPCOUNT= @LOOPCOUNT+1
END
COMMIT

SET STATISTICS TIME ON
SELECT COUNT_BIG(*) FROM Fragmented where Primarykey=1000
SET STATISTICS TIME ON

In the above image you can see while the Index was Rebuilding, it was available (Online) and the above select query completed immediately.
Demo: Rebuild Creates The New Index
We have just rebuilt the index and before Rebuilding the index we have checked its Object ID and Index Pages, let us use again the sys.dm_db_database_page_allocations DMV and look inside the index.
SELECT
object_id AS ObjectID ,index_id AS IndexID ,page_type AS PageType ,page_level AS IndexLevel
,previous_page_page_id AS PrevPagePID ,allocated_page_page_id AS PagePID,next_page_page_id AS NextPagePID
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Fragmented'), 1, NULL, 'DETAILED')
WHERE is_allocated = 1 and page_type=1 and page_level=0
ORDER BY previous_page_page_id;
Look at the above result set a new ObjectID and a new set of Page IDs (compare these results from the first demo) and those pages are in order, look it as "PrevPageID -> PAgeID -> NextPage", if you are interested in the
index internal then click on the hyperlink.
Rebuild Can Run In Parallel
The fourth point we are covering in this demo is that the Rebuild can run in parallel, but it depends on the version I have a SQL Server 2017 developer version which offers all features of the enterprise edition free for development only, so it should show the rebuild operation in the parallel look into the execution plan and trace flag event collected:


Yes, they both suggest that the Rebuild Process executed in the parallel mode.
Rebuild Is An Atomic Process:
In this demo we will use the stored procedure DropCreateAndFragmented to recreate the Index, then we will see the index pages again using sys.dm_db_database_page_allocations then we will rebuild the index and then cancel it in the middle and we will see the Index Pages, does the Index`s Object IDs and Pages has changed since the last test or not let us see this in this demo below:
EXEC DropCreateAndFragmented
GO
SELECT
object_id AS ObjectID
,index_id AS IndexID
,page_type AS PageType
,page_level AS IndexLevel
,previous_page_page_id AS PrevPagePID
,allocated_page_page_id AS PagePID
,next_page_page_id AS NextPagePID
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Fragmented'), 1, NULL, 'DETAILED')
WHERE is_allocated = 1 and page_type=1 and page_level=0
ORDER BY previous_page_page_id;
ALTER INDEX ALL ON Fragmented REBUILD
-- AFTER CANCEL REBUILD IN MIDDLE
SELECT
object_id AS ObjectID
,index_id AS IndexID
,page_type AS PageType
,page_level AS IndexLevel
,previous_page_page_id AS PrevPagePID
,allocated_page_page_id AS PagePID
,next_page_page_id AS NextPagePID
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Fragmented'), 1, NULL, 'DETAILED')
WHERE is_allocated = 1 and page_type=1 and page_level=0
ORDER BY previous_page_page_id;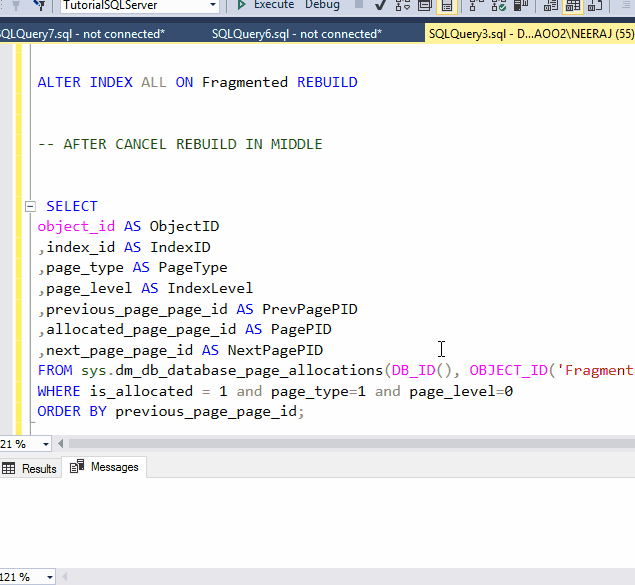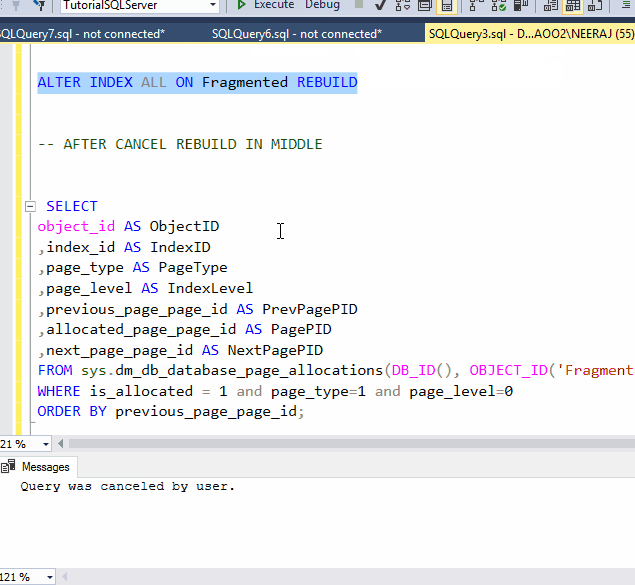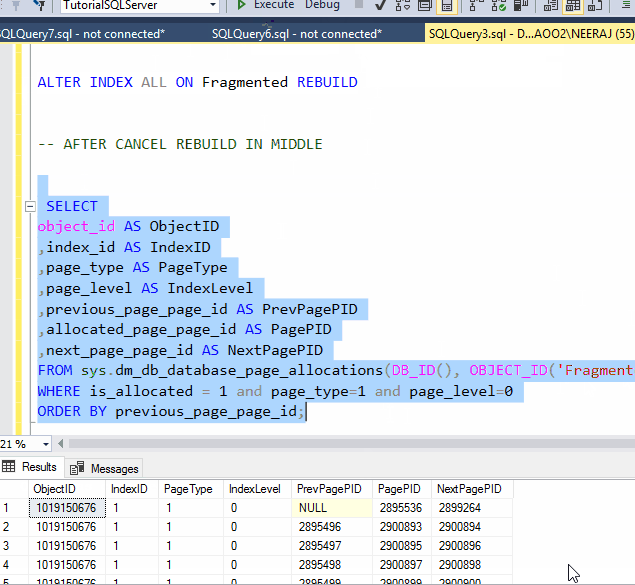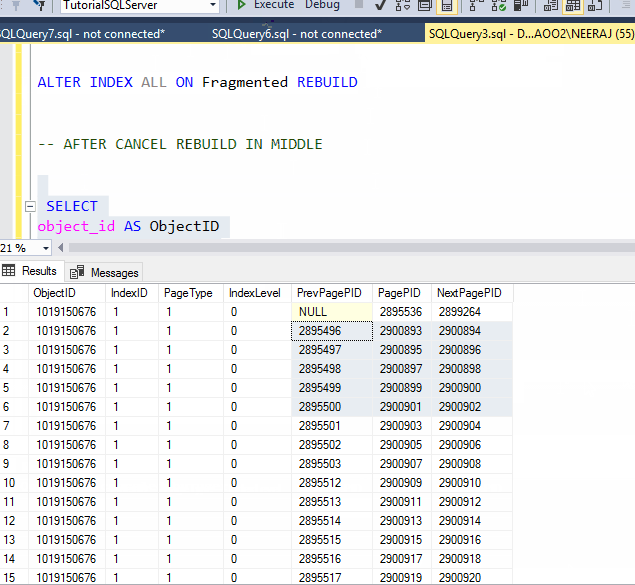
See in the above GIF we have cancelled the rebuild process in the middle of execution and the ObjectID and Page IDs hasn`t change, it conclude that rebuild is an atomic process, either all the changes will reflect or none.
Rebuild Index Log GenerationAgain, it's a small test which will show how much transaction log generated when we Rebuild this table, first we will see the data size of the table using the SP_Spaceused, then we will Rebuild the Index and capture the transaction log activity by using dm_tran_database_transactions DMV, see the query and result below:
SP_SpaceUsed 'Fragmented'

BEGIN TRAN
ALTER Index All ON Fragmented REBUILD
SELECT [database_transaction_log_bytes_used] FROM sys.dm_tran_database_transactions
WHERE [database_id] = DB_ID ('TutorialSQLServer');
COMMIT
Look at the both outputs, the output of the Transaction Log and data space in the table is nearly same.
This isn`t a coincidence, because Rebuild operation creates a new Index thus it logged all the data pages plus some additional overhead while creating the Index.
REORGANIZED INDEX
Here it the bullet point list about the Reorganize index below:
- It does not drop the index, it just shuffled the leaf pages to remove the fragmentation.
- Always single threaded operation.
- Reorganized always perform online, thus there is no downtime irrespective of the version and edition of SQL Server.
- A non atomic process, even if you stop the reorganize process in between the operation, it can start from where it left.
- It usually takes more time to de-fragmented the Index.
- It does not update nor create statistics on the underlying Index.
- If the Index is never reorganized, then it can generate lots of logs record because it is fully logged operation.
DEMOIn this section we will repeat the tests what we have done with the Rebuild, everything will be same the difference would be only this time we are reorganizing the index:
Demo: Reorganize is Non Atomic ProcessFirst, let us use the DropCreateAndFragmented store procedure to create a fresh fragmented index, then we will see inside of the index using sys.dm_db_database_page_allocations DMV, then we will reorganize it and cancel in the middle of the operation , again we will look into sys.dm_db_database_page_allocations DMV.
Exec DropCreateAndFragmented
GO
SELECT
object_id AS ObjectID
,index_id AS IndexID
,page_type AS PageType
,page_level AS IndexLevel
,previous_page_page_id AS PrevPagePID
,allocated_page_page_id AS PagePID
,next_page_page_id AS NextPagePID
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Fragmented'), 1, NULL, 'DETAILED')
WHERE is_allocated = 1 and page_type=1 and page_level=0
ORDER BY previous_page_page_id;
ALTER INDEX ALL ON Fragmented REORGANIZE
-- AFTER CANCEL REORGANIZE IN MIDDLE
SELECT
object_id AS ObjectID
,index_id AS IndexID
,page_type AS PageType
,page_level AS IndexLevel
,previous_page_page_id AS PrevPagePID
,allocated_page_page_id AS PagePID
,next_page_page_id AS NextPagePID
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Fragmented'), 1, NULL, 'DETAILED')
WHERE is_allocated = 1 and page_type=1 and page_level=0
ORDER BY previous_page_page_id;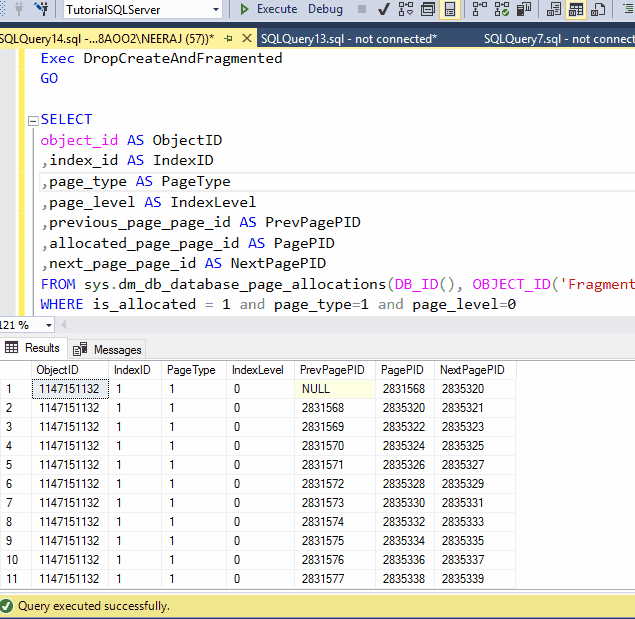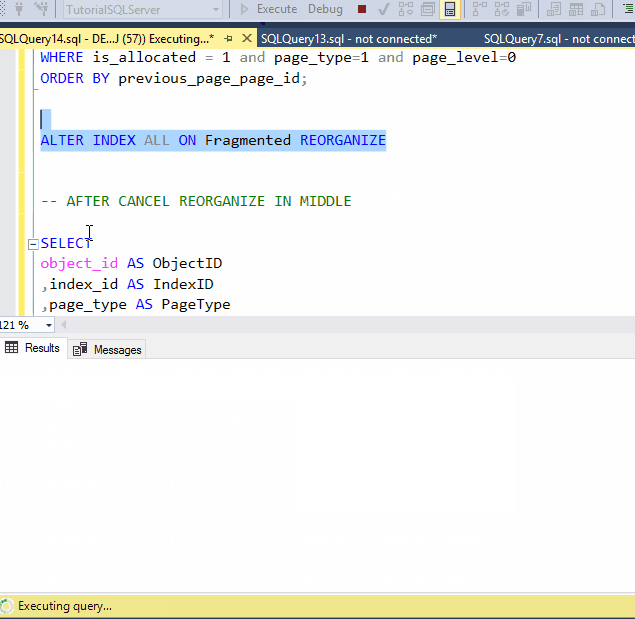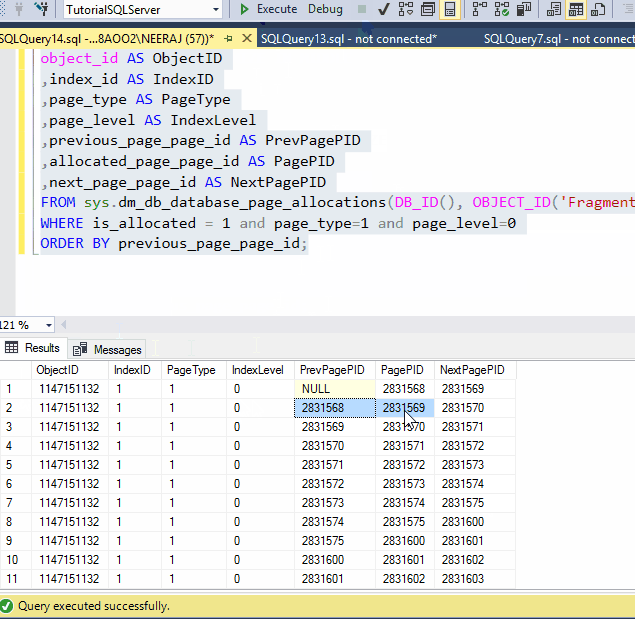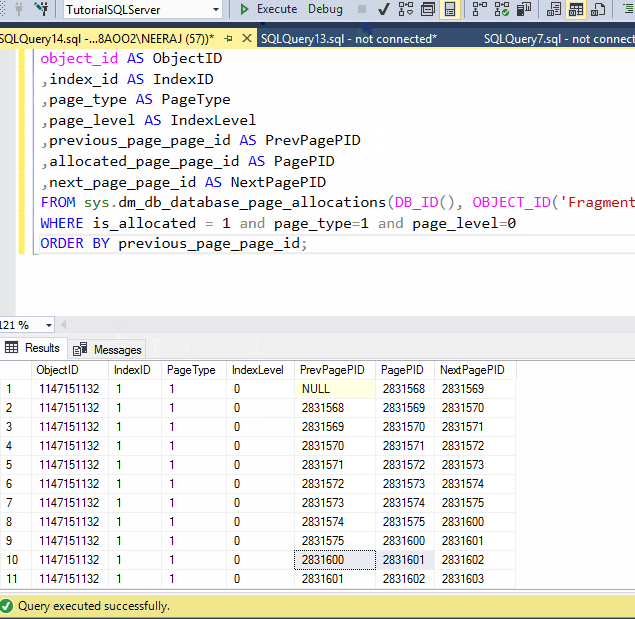
Look this Reorganize process it took more than 9 seconds on my system, whereas rebuild takes not more that 4 second.
We have cancelled the reorganized operation, but still we can see the PageID of index are in order,
If you look closely in the data pages you will find the PageIDs has changed, the reason behind that is reorganize shuffle the pages to remove the fragmentation and can allocate new pages to the existing data, if the Index is heavily fragmented, but it does not create a whole new index, if you try to find the pages which were in the index before Reorganize Index, you might find it and when you see data inside the pages you probably see some new data in the data page.
If you want we can make a new short article on that, just comment below.
Reorganize Doesn`t Create A New IndexIt is again a short demo which shows that Reorganize doesn`t create a new Index, In this demo we will reorganize the index and we will check does the Index ObjectID and PageIDs changed in comparewith the last demo.
Script and result below:
ALTER INDEX ALL ON Fragmented REORGANIZE
GO
SELECT
object_id AS ObjectID
,index_id AS IndexID
,page_type AS PageType
,page_level AS IndexLevel
,previous_page_page_id AS PrevPagePID
,allocated_page_page_id AS PagePID
,next_page_page_id AS NextPagePID
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Fragmented'), 1, NULL, 'DETAILED')
WHERE is_allocated = 1 and page_type=1 and page_level=0
ORDER BY previous_page_page_id;
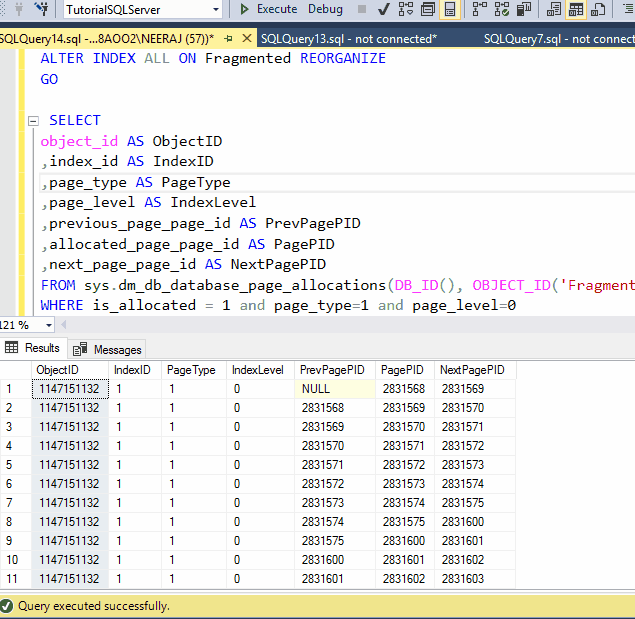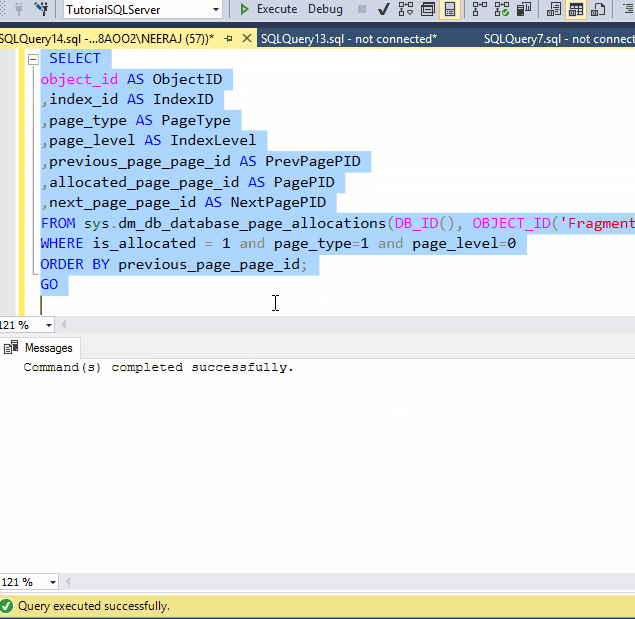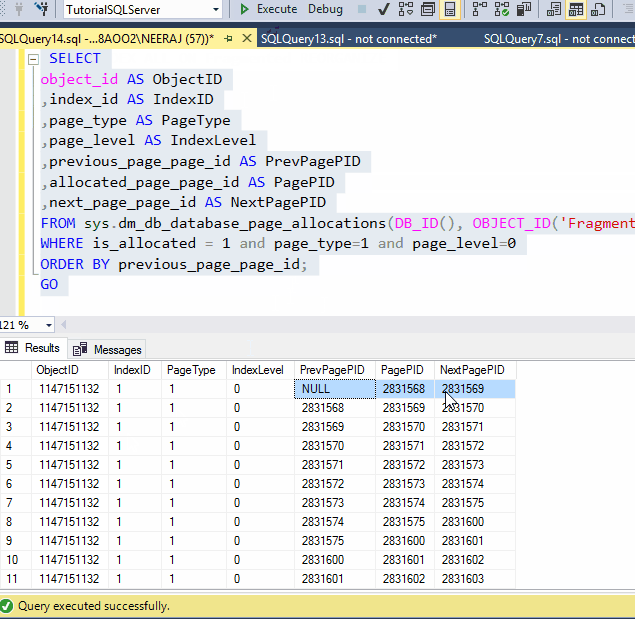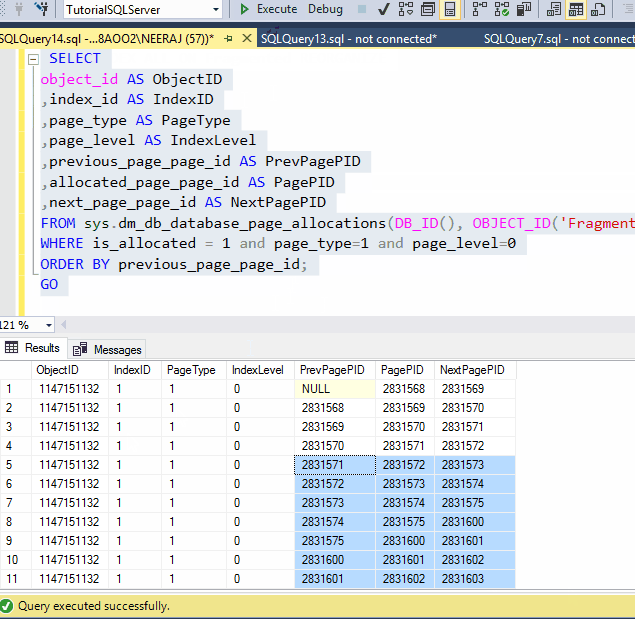
Look at the above GIF after rebuilding the Index still the PageIDs are same as being in the last tests.
One bonus tip: this time rebuild has finished very quickly, the reason is, Rebuild can start working exactly from where it stops from the last point, thus you won't lose the progress, that is a great feature of reorganized and very useful for large indexes.
Reorganize Is An Online Process:Ok, because we have a small clustered index, which will rebuild very quickly and we need to check whether rebuild is offline process or not we will run it in a loop 5 times and simultaneously we will run a simple select query in another query window simultaneously:
--QUERY WINDOW 1
DECLARE @LOOPCOUNT INT
SET @LOOPCOUNT=1
WHILE( @LOOPCOUNT <=5)
BEGIN
ALTER INDEX ALL ON Fragmented REBUILD
SET @LOOPCOUNT= @LOOPCOUNT+1
END

--QUERY WINDOW 2 (SIMULTANEOUSLY RUN WITH REORGANIZE)
SET STATISTICS TIME ON
SELECT COUNT_BIG(*) FROM Fragmented where Primarykey=1000
SET STATISTICS TIME ON

Here we go, unlike the last time when we were rebuilding the Index, the Index wasn`t available, this time Index is online and we are able to access it during the reorganizing the index.
I tried to capture Execution Plan and Trace Flag to conclude it is a single threaded operation,But neither of them captured.
Reorganize Index Log Generation
Now here is the final demo of Reorganize the Index, it generates lots of Transaction Log records, a very simple demo, we will capture transaction log using sys.dm_tran_database_transactions DMV:
BEGIN TRAN
alter index all ON Fragmented REORGANIZE
SELECT [database_transaction_log_bytes_used] FROM sys.dm_tran_database_transactions
WHERE [database_id] = DB_ID ('tutorialsqlserver');
COMMIT
We can clearly see in the above output Reorganize process generated 132431128 bytes of records, whereas with the Rebuild process it generated 57486428 bytes for transaction log only.
We have seen all the difference with the proper demos what are the advantages and disadvantages of Rebuild and Reorganization process, let us summarize the difference quickly:
REBUILD
| REORGANIZE
|
Rebuild drop the existing index and recreate a brand new Index.
| It does not drop the index, it just shuffled the leaf pages to remove the fragmentation
|
Rebuild can run in parallel (enterprise/developer version only), this is a great feature for large table so it leverage all CPUs and performs the operation faster.
| Always single threaded operation.
|
Since Rebuild creates a fresh index so it create new and fresh statistics as well on the underlying index.
| Reorganize never creates a new index nor statistics.
|
| If rebuild is performed offline then the index will not available until the rebuild process has completed, and to perform the online rebuild you should
have an expensive enterprise edition only, since the index rebuild, Recreate the entire index. | Reorganized always perform online, thus there is no downtime regardless of the version and edition of SQL Server.
|
Rebuild is an atomic operation means if you cancel it in between it will stop and reflect no change.
| A non atomic process, even if you stop the recognize process in between the operation, it can start from there next time from where it left.
|
| Rebuild indexes generate an almost similar amount of log for the same size index. | If the index is never reorganized, then it can generate lots of log records.
|
| You can specify a fill factor setting while rebuilding the index. | Can not specify fill factor.
|
Now we have a basic idea what is Rebuild and Reorganized, we can take a decision when to rebuild and when to reorganize, choosing one technique over another on the fragment index depends on some criteria like: what is the index size, what is the business type, can you afford the downtime how much the index is fragmented etc etc.
For example, you have a large fragmented index and you want it to defragment it, but your production system does not allow downtime and you are working on standard edition then you cannot Rebuild the Index, since "online on" is not allowed on the standard edition and your production server cannot afford the downtime.
So the point is there are uses and cases where one is preferred over another.
Fill Factor In SQL Server Defagmentation of index helps the reads to perform better, but we have seen
writes is also a problem when a page split occurs, which leads to fragmentation, is there a way to mitigate this problem?
Yes, there is, it is the process to create internal fragmentation to some extent so when a row tries to insert or any variable length column expand, then there should be some space available to adjust the new data.
This is called Fill Factor.
Ok, so let us use again our example and see how fill factor works:
SQL Server Fill Factor Example:In the last part of the series, we used readfragmented table and fragment it heavily by
Inserting the primary key, if you have not visited the
last part we recommend you to visit
the last part for better understanding this subject In this section we will again fragment the index, but this time we will use the fill factor to save it from the fragmentation.
Let us go ahead and setup the table again:
DROP TABLE [DBO].Fragmented
CREATE TABLE [DBO].Fragmented (
Primarykey int NOT NULL,
Keycol VARCHAR(50) NOT NULL
,SearchCol INT
,SomeData char(20),
Keycol2 VARCHAR(50) NOT NULL
,SearchCol2 INT
,SomeData2 char(20),
Keycol3 VARCHAR(50) NOT NULL
,SearchCol3 INT
,SomeData3 char(20))
GO
INSERT INTO [DBO].Fragmented
SELECT
n,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
FROM Numbers WHERE N/2.0=N/2
AND N<500001
GO
CREATE UNIQUE CLUSTERED INDEX CI_Fragmented ON [DBO].Fragmented (Primarykey)
--Only added part
WITH (FILLFACTOR = 47 , MAXDOP =1)
GO
The example we are using of setting the fill factor is extreme and in the real world we usually set a low number in fill factor, do not forget in the last part of the series we show how internal fragmentation can be much more expensive than from the external fragmentation.
You know your database workload type it`s your responsibility to decide the best number of fill factor.
The best practice is to set a high number (90 or 95) for fill factor and monitor fragmentation and change upward or downward accordingly.
Now look at the image above, Page Density is approx to 47 percent, page count are 7307 and number of records are
250000 in the leaf level of index.
SELECT OBJECT_NAME(OBJECT_ID) Table_Name, index_id,index_type_desc,index_level,
avg_fragmentation_in_percent fragmentation, avg_page_space_used_in_percent Page_Density, page_count,Record_count
FROM sys.dm_db_index_physical_stats
(db_id('TutorialSQLServer'), object_id ('Fragmented'), null, null,'DETAILED')
Where
Index_Level =0 and Index_Id=1
Let us insert even number in the index and monitor fragmentation again:
INSERT INTO [DBO].Fragmented
SELECT
n,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
,
n,
n
,'Some text..'
FROM Numbers WHERE N/2.0!=N/2
AND N<500001
GO
SELECT OBJECT_NAME(OBJECT_ID) Table_Name, index_id,index_type_desc,index_level,
avg_fragmentation_in_percent fragmentation, avg_page_space_used_in_percent Page_Density, page_count,Record_count
FROM sys.dm_db_index_physical_stats
(db_id('TutorialSQLServer'), object_id ('Fragmented'), null, null,'DETAILED')
Where
Index_Level =0 and Index_Id=1
Still, the Index is not externally fragmented and more importantly, we can say Page Split didn`t occur during the process.
So we can say Fill Factor is a tool to avoid the external fragmentation by introducing internal fragmentation in the index :).
Fill factor is a great tool to avoid page splits event in the OLTP environment, but it is not required in a pure OLAP environment so what Fill a factor value you should decide always depends on your workload ad environment.
To remove the fragmentation, some organizations create a maintenance plan and schedule it according to the requirement of database, there are some maintenance plan scrip is available online, one of the most popular is Ola Hallengren
maintenance script.
You can consider it in your maintenance plan as it does fantastic job you can visit here or more information.
There is a great presentation on fragmentation by Paul Randal you can watch it below.
https://www.youtube.com/watch?v=p3SXxclj_vgConclusion
Technologies and hardware changes very fast, even with some hardware type you might find that index read was performing better
when it was fragmented, RAM is not expensive as it use to be in early days back then external fragmentation use to matter a lot, but this a
not a big problem now.
To be honest the root of better performing database lies in better database design and skilled query writing.
I hope you enjoyed the entire series what is your thought about this topic and the series?
QUOTE“If you can't fly then run, if you can't run then walk, if you can't walk then crawl, but whatever you do you have to keep moving forward.” Martin Luther King Jr.